
Jest async test: A developer’s tutorial
Jest is one of the most commonly used test frameworks for JavaScript testing. With the rise of asynchronicity in modern web development, it’s important to know
In the world of Big Data, decentralization is king.
Seeing that today’s data sets are so large and complex that traditional database systems cannot handle them, distributed deep learning splits computational problems that require high storage and solving time into many subproblems that can be assigned to multiple machines. This enables data scientists to massively increase their productivity by running parallel experiments over many devices (servers, GPUs, TPUs), following the age-old idiom, “Many hands make light work.”
While terms like AI, machine learning, and deep learning are sometimes used interchangeably, they’re more like subsets of one another. The field of artificial intelligence encompasses a broad area of research and engineering, while machine learning is a subset of the field of AI, and deep learning is a highly specialized form of machine learning.
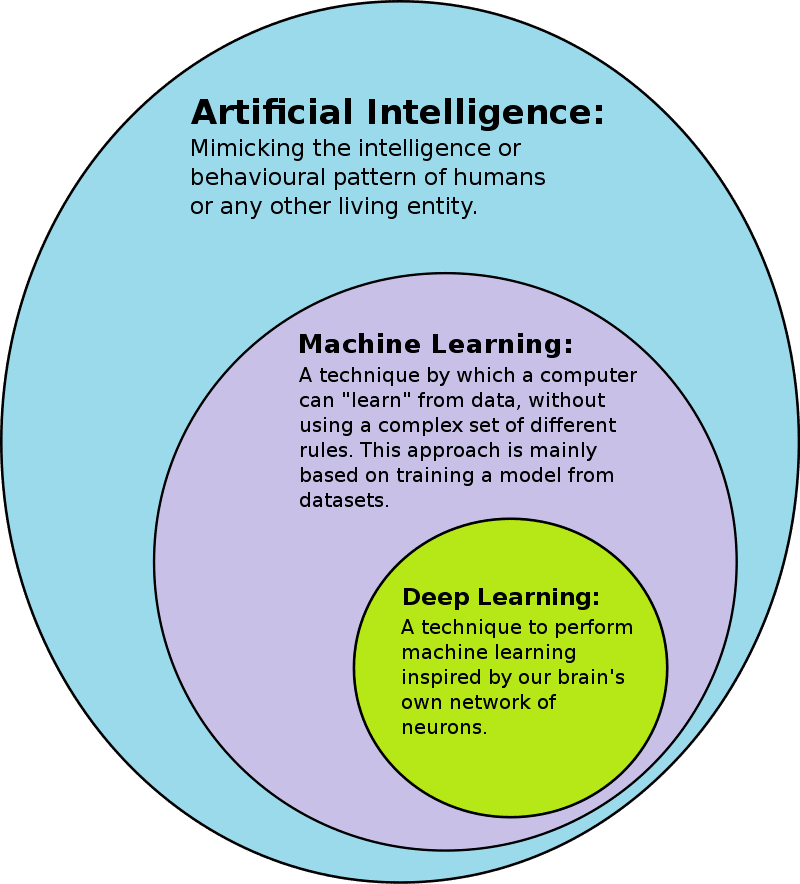
The concept of artificial intelligence has been around since the 1950s, with the goal of making computers able to reason and think in a way similar to humans. Machine learning came later to focus on the techniques and paradigms of how machines can learn to act in different environments and make meaningful choices independent of human intervention. Traditional deep learning on the other hand creates more complex hierarchical models meant to mimic how the human brain learns new information.
The category of distributed deep learning is a relatively new subset of deep learning. It goes beyond traditional deep learning in that it allows for profound scalability (for larger volumes of data) by allocating learning processes across multiple distributed (decentralized) workstations. In contrast, traditional deep learning is centralized in the sense that it is accomplished in a single machine.
This post explores real-world examples of distributed deep learning to shed light on how it works and how it can benefit teams looking to increase their productivity. If you’re already familiar with this concept and want to skip through to the use cases, use the menu below:
Distributed deep learning consists of a collection of autonomous computing elements that act as a whole, coherent system. Machines that form part of this virtual network converse with one another to synchronize and order any actions requested by users, such as acquiring, cleaning, processing, analyzing, storing, and programming machine learning models using Big Data. Meanwhile, programmers can continually re-train algorithms by using parallel loading so as not to interrupt workflow.
Typically, distributed deep learning systems follow these steps:
Distributed systems allow researchers to draw meaningful conclusions from enormous data sets in an efficient way. Given the rapid emergence of services that rely on data for boosting productivity–with 94% of business and enterprise analytics professionals recognizing that data and analytics are critical to their organization’s digital transformation programs–, it is highly likely that data analytics will be primarily accomplished in distributed environments. Against this backdrop, many other advantages are presented by distributed deep learning, including:

However, all new technologies come with their unique set of challenges and room for improvement. When it comes to distributed deep learning’s, here’s what to keep in mind:
As we’ve seen, in distributed training the workload to train a model is split up and shared among multiple nodes which work in parallel to speed up model training. While distributed training can be used for traditional machine learning models, it is better suited for compute- and time-intensive tasks like deep learning, where two main types of distributed training can be used: Data parallelism and model parallelism.
Used more frequently than model parallelism, data parallelism is a technique that distributes data across multiple machines in order to achieve faster training and computation of the data. To use this method, start by dividing the data into partitions, with the number of partitions equal to the number of nodes (worker machines) in the compute cluster. The model is copied in each of these worker nodes and each node owns performs computation over its own subset of the data. This implies that each node must have the capacity to support the model that’s being trained.
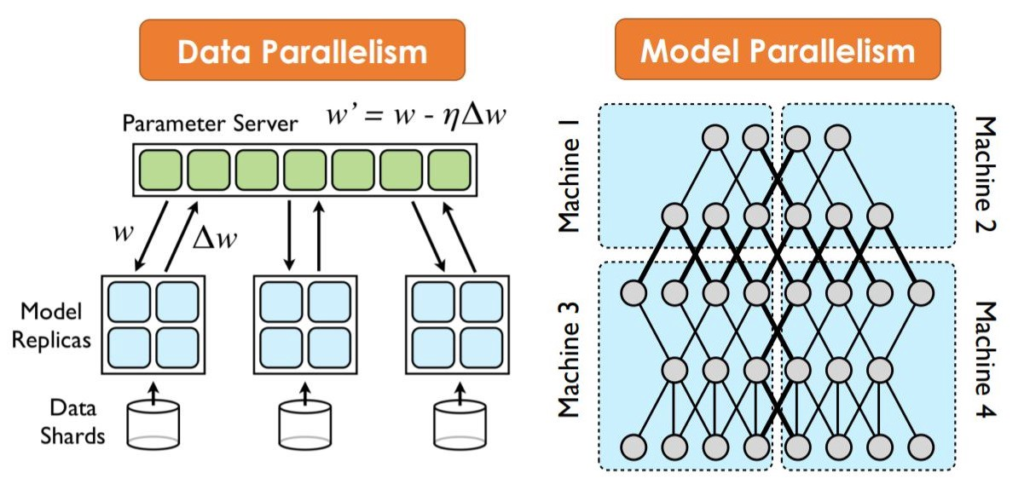
Also known as network parallelism, this is a more complex concept to implement than the previous. Whereas data parallelism distributes data, model parallelism distributes the machine model itself so that the segmented model can run concurrently in different nodes, and each one will run on the same data. This is done when neural network models become so large that they can’t be saved into a single machine.
To apply model parallelism, the matrix must be partitioned into many small blocks so that each worker takes care of a few. In this way, it’s possible to leverage the additional RAM of multiple nodes if the RAM on one node can’t store all the parameters in the matrix. Since different nodes have different workloads that map to different blocks of the matrix, we should get a higher performance speed when they compute in parallel.
By exploring and resolving human problems in nearly every domain, distributed deep learning is impacting entire industries the world over. Here are six use cases that illustrate how this technology comes to life and how it may help you, too:
Over the last few years, voice assistants have become ubiquitous with the popularity of Siri, Amazon Echo, Google Home, and Cortana. These are the most well-known examples of Automatic Speech Recognition (ASR), also known as Speech-to-text algorithms. Each interaction with these assistants provides the AI with an opportunity to learn more about your voice and accent, so it can provide you with a secondary human interaction experience.
Beyond consumer products and entertainment, examples abound, with customer care, healthcare, and financial institutions emerging as major end-use markets for the technology. In health and social care, for example, voice-recognition software is being used to help those with physical disabilities who might find typing difficult, painful, or impossible. Rising demand for speech-based biometric systems for carrying out multifactor authentication is another major factor driving growth in the market.
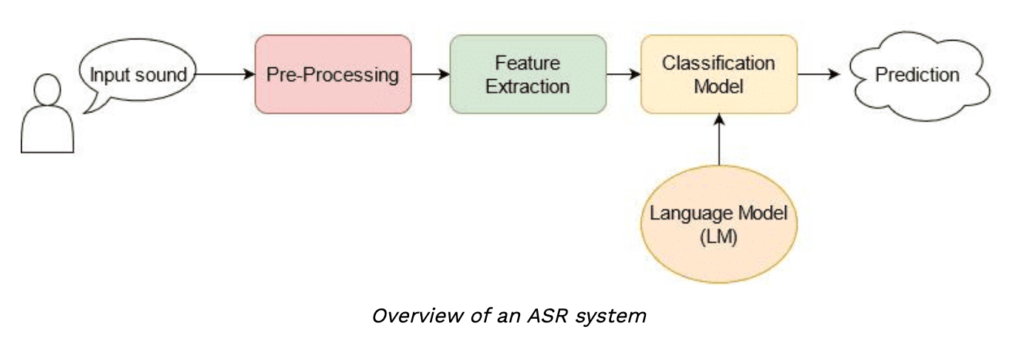
Up until recently, audio machine learning applications depended on traditional digital signal processing techniques to extract features. For example, to understand human speech, audio signals were analyzed using phonetics concepts to extract elements like phonemes. A lot of domain-specific expertise was needed to solve these problems and tune the system for better performance. Now, with distributed deep learning, experts rely on standard data preparation without requiring a lot of manual and custom generation of features.
ASR has gained a lot of attention over the last decades, with early methods focused on manual feature extraction and conventional techniques such as Gaussian Mixture Models (GMM), the Dynamic Time Warping (DTW) algorithm, and Hidden Markov Models (HMM). More recently, neural networks such as recurrent neural networks (RNNs), Convolutional neural networks (CNNs), and Transformers have been applied to ASR and have achieved great performance.
Large-scale image recognition through distributed deep learning is boosting growth in digital media management with applications like Tensorflow and Python. Image Recognition is a wide arena to be explored as it can be leveraged in various applications such as face recognition, medical diagnosis, number scanning, and handwriting recognition. The challenge they all have in common is that of increasing accuracy without increasing the time required for training and testing models, which remains a key area of interest among deep learning experts.
Understanding the complexities associated with language (semantics, syntax, expressions, tonal nuances, or even sarcasm), are some of the hardest tasks for humans to learn. NLP through distributed deep learning is trying to achieve the same by training machines to catch linguistic nuances and frame appropriate responses. NLP-based systems have enabled a wide range of applications such as Google’s search engine, and Amazon’s voice assistant Alexa.
NLP is also useful to teach machines the ability to perform complex natural language related tasks such as dialogue generation and machine translation. In the past, the majority of methods used to study NLP problems utilized shallow machine learning models and time-consuming, hand-crafted features. However, with the recent popularity and success of word embeddings (which are low dimensional, distributed representations), distributed deep learning models have achieved superior results on various language-related tasks.
More and more CRM companies are using distributed deep learning to enhance their tool, seeing AI and CRM as the most potent combo in the industry today. And it’s easy to see why: Distributed deep learning can help predict consumer behavior, act as a sales assistant, generate predictive lead scores, assist in creating targeted content, and even automate service desk functions. Additionally, it can help businesses automate regular processes, provide quick replies to customers outside of staff working hours, and provide correct insights to sustain business growth.
Also benefitting from distributed deep learning is the financial and banking sector, which is plagued with the task of detecting fraud within digital transactions worldwide. Fraud prevention and detection are based on identifying patterns in customer behavior such as transactions and credit scores, to identify anomalous activities. Classification and regression machine learning techniques along with distributed deep learning automate the task of tracking the relevant red flags at scale, thus detecting fraud while minimizing human effort.
Social media and big tech are getting in on the distributed deep learning action. Facebook has been using AI for years (Facebook AI Research Lab) to try to solve problems for users and improve its UX. Facebook’s AI software analyzes photos, videos, and stories users have previously interacted with then gathers up recommendations so that they are served relevant content.
Facebook recently recognized the need for better technology for unlocking the full potential of augmented reality (AR) and virtual reality (VR), so it created the Oculus Quest, a wire-free VR system that calculates users’ movements and positions at every millisecond, then translates those movements into VR. This new technology reduces or eliminates some of the problems associated with previous VR headsets (latency, jitter, visual stuttering).
A similar example can be seen on Instagram, where over half of its 500 million daily users visit the Explore feature to find personalized, curated recommendations that are powered by AI.
Meanwhile, Google’s DeepMind Technology was used to improve power efficiency in the data centers at Google. DeepMind was able to improve on the efforts of previous specialists by 15%, making a 40% reduction in cooling costs. It’s also been instrumental in developing Google Assistant and helps create personalized recommendations in Google Play.
From all we’ve learned so far, it’s clear that harnessing the power of distributed deep learning can lead to some drastic performance increase. But distributed deep learning can also open a can of security risks as it by definition relies on data sharing at scale. Wherever you are in the Big Data pipeline, you’re likely at risk for security errors that can result in data leakage, even if you’ve implemented best practices for securing your code.
To eliminate public blind spots across your multiple data sources through automated codebase scanning that covers your entire software development lifecycle, check out the SpectralOPs demo today.

Jest is one of the most commonly used test frameworks for JavaScript testing. With the rise of asynchronicity in modern web development, it’s important to know
![Medical Device Security Risk Assessment [Download XLS Template]](https://spectralops.io/wp-content/uploads/2023/09/73d8b64b-9461-4e68-b897-bfb1cf3466a2-48-335x176.png)
When you think about hacking stuff, you probably don’t consider thermometers and pacemakers. But imagine the implications if that chunk of metal inside your body suddenly

Welcome to the world of Docker containers, where the power of isolation and portability meets streamlined application development. Whether you’re an experienced Docker user or just