
6 Essentials for a Near Perfect Cyber Threat Intelligence Framework
Software developers face a constant barrage of cyber threats that can compromise their applications, data, and the security of their organizations. In 2023, the cyber threat
The encoding scheme you choose as a developer can have far-reaching consequences for your application’s functionality, security, and performance–in other words, it could be the difference between a seamless user experience and a catastrophic data failure.
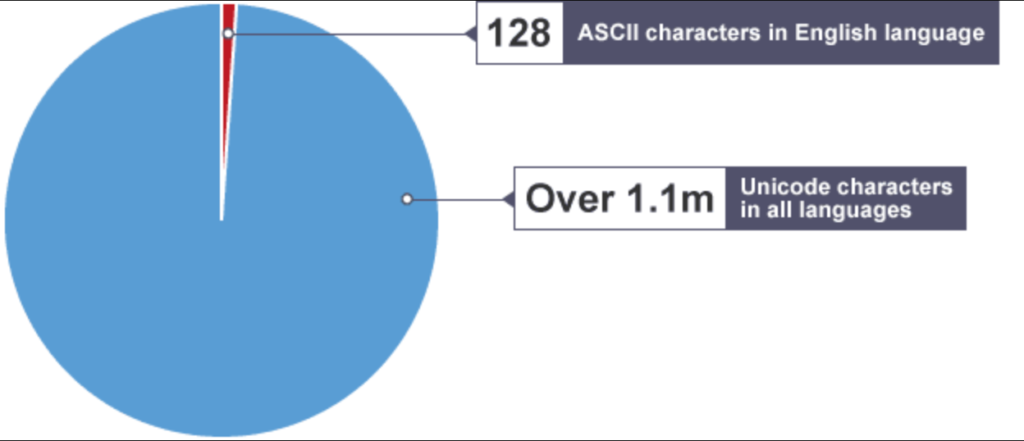
ASCII is a popular choice, with over 95% of all websites using it, and Unicode is quickly gaining ground for many applications on over 60% of websites. This article focuses on these two, even though there are many other encoding options to consider.
Whether you’re developing a website, mobile app, or software, choosing the right scheme for your use case is essential. Let’s demystify the worlds of ASCII and Unicode encoding to ensure your next project is successful.
Encoding schemes define how characters and symbols are represented in digital form, which impacts how data is stored, processed, and transmitted. That’s why developers need to choose an encoding scheme that best fits the specific requirements of their use case, be it a software, website, or mobile app.
Encoding should not be confused with encryption or hashing. Encryption is converting data into code to protect it from unauthorized access. For example, encryption secures sensitive information such as passwords, credit card numbers, and personal data. On the other hand, hashing is a one-way function that converts data into a fixed-length string of characters. For example, hashing is commonly used to store passwords securely in a database.
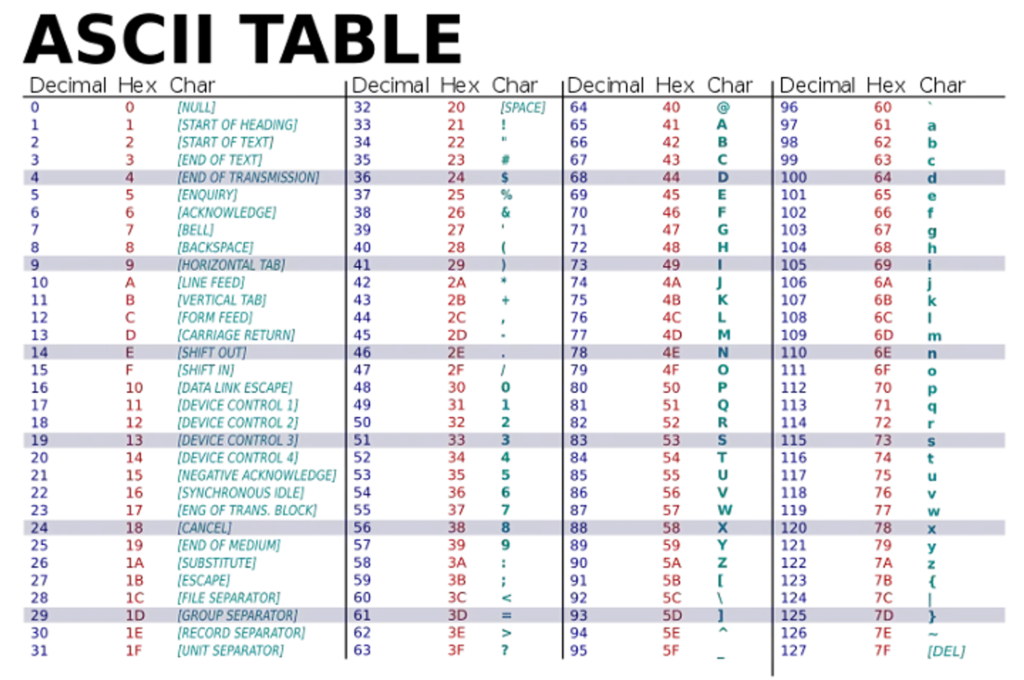
Although still widely used, ASCII (American Standard Code for Information Interchange) was developed in the 1960s as the first major character encoding standard for data processing. It is used to represent numbers (0-9), the English alphabet (A-Z) in uppercase and lowercase, and some symbols (including punctuation marks).
Despite its popularity, ASCII has some limitations. A major one is that it can only be used to encode characters in the English language, making it impractical for languages that use different alphabets and characters, such as Hebrew, Arabic, Hindi, Japanese, and Chinese.
Still, as we’ll see, ASCII is supported by most modern computer systems and is the basis for many other character encoding standards, including Unicode.
ASCII uses 7 bits to represent a total of 128 characters. With the widespread use of 8-bit computers, an extended ASCII table was developed that uses 8 bits to represent 256 characters.Each character is assigned a unique numerical value (an ASCII code) ranging from 0 to 127. For example, the ASCII code for the letter “A” is 65, while the ASCII code for the number “1” is 49.

When data is encoded using ASCII, each character in the text is converted into its corresponding ASCII code, which is then stored as a sequence of binary digits (0s and 1s). This binary representation of the data can be transmitted from one computer to another, where it can be decoded back into the original text.

Insecurity: ASCII is also vulnerable to security issues, such as character substitution attacks, where a malicious actor replaces characters in the data to alter its meaning or cause harm. This is a particularly serious issue in applications that transmit sensitive information, such as financial transactions or medical records.

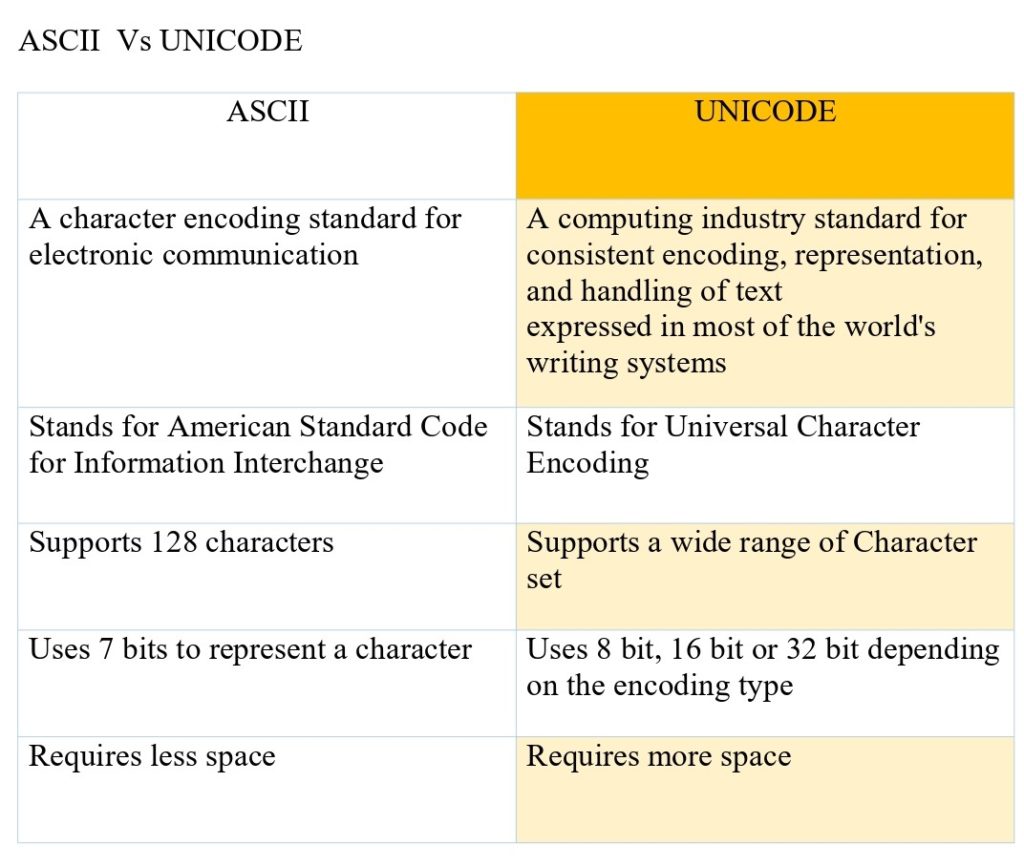
Unicode is a computing industry standard introduced to address the limitations of character encoding systems such as ASCII. It provides a standardized, universal character set that covers various characters in different scripts and languages, including Latin, Greek, Cyrillic, Hebrew, Arabic, Hindi, Chinese, and many more.
Unicode contains over 100,000 characters, making it possible to encode text in any written language used today. Using several encoding formats known as UTF (Unicode Transformation Format), Unicode can represent characters as binary data that computers can process. UTF-8 is the most widely used encoding format for web content.
Unicode has become the standard for character encoding in the computing industry, and its widespread use has helped to eliminate data exchange problems between systems that use different encoding systems. In addition, it allows developers to create user-friendly interfaces that can be used by people speaking different languages, and it helps to simplify tasks related to data processing and information management.
Unicode assigns a unique number, called a code point, to each character in the universal character set. These code points represent the characters in binary form using one of the encoding formats specified by Unicode, such as UTF-8, UTF-16, or UTF-32.
When text is stored in a computer system, the code points for each character are first assigned and then encoded into a binary form using one of the Unicode encoding formats. The encoding format determines the number of bytes used to represent each character and affects the storage space required and the processing speed.
When text is displayed, the binary representation of the code points is decoded back into characters, which can then be displayed on the screen. The process of encoding and decoding ensures that the text is stored and transmitted accurately, regardless of the platforms, applications, or languages involved.
Some legacy systems may not fully support Unicode, leading to compatibility issues and the need for conversion and migration to newer systems.

Here are some factors to consider when choosing between ASCII and Unicode for your specific use case:
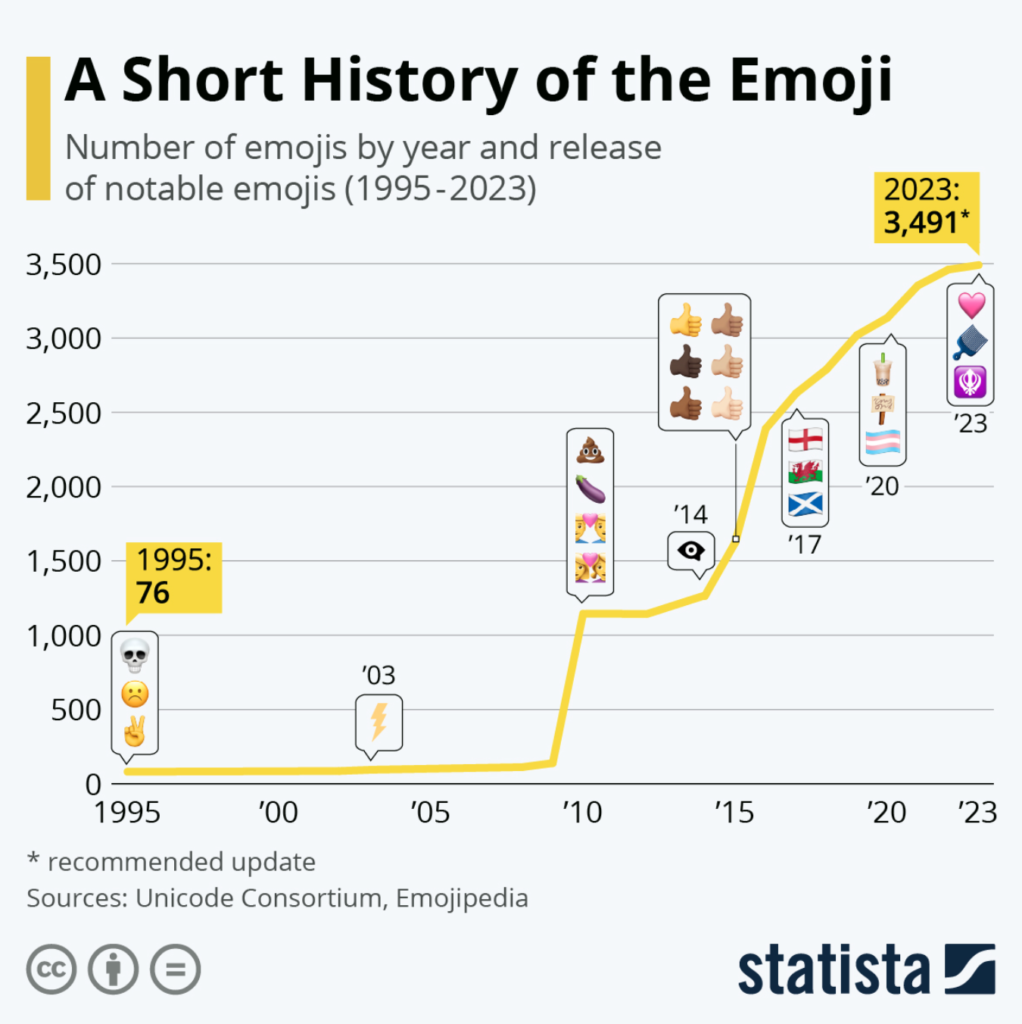
Plans: when considering the project’s future, remember that Unicode is the standard for modern computing and can represent a wider range of characters than ASCII. To put things in perspective, take the booming popularity of emojis, used by 92% of people online, according to the Unicode Consortium. Unicode can give you the flexibility to accommodate these types of trends if user experience is top of mind for you.
When selecting the right encoding system for your DevOps project, it is critical to consider language support, storage requirements, data transmission, compatibility, security and plans. But don’t let security be an after-thought. Matching early encoding decisions with automated security solutions could improve results, code safety, and long-term trust. For example, a solution like Spectral can help developers detect hard-coded secrets and prevent source code leakage, a common problem associated with encoding. To code confidently while protecting your company from expensive mistakes, learn more and get started with a free account today.

Software developers face a constant barrage of cyber threats that can compromise their applications, data, and the security of their organizations. In 2023, the cyber threat

The number of secrets exposed in public repositories is staggering. With reports in 2021 reaching up to 6 million secrets detected, an increase of 50% from

Becoming and staying PCI compliant both take a lot of work. Developers are often already swamped with an endless list of tasks, and adding PCI compliance