
Identity Governance: What Is It And Why Should DevSecOps Care?
Did you know that the household data of 123 million Americans were recently stolen from Alteryx’s Amazon cloud servers in a single cyberattack? But the blame

Teller is an open-source secrets management tool for developers built in Go. It helps you manage, protect, and fix problems in your code and security posture when it comes to your vaults and key stores. Teller also lets you securely control all of your stores in one place.
In addition, Teller encourages developer environment hygiene. Acting as a process runner, it will never give a child process being run secrets that the owning shell process may contain. Every process is run with a context that is on a need-to-know basis.
If you’re part of a modern development team or a growing organization, it is very easy to find yourself looking at an architecture that uses multiple cloud providers, employing different building blocks from each to optimize for various important concerns (such as scale, cost, as well as speed, and ease of development).
In the blueprint below, we see a typical solution. In it, the main app (read-heavy) is built on Heroku and some other API built as a microservice for ingesting events (write-heavy) built for scaling dynamically on AWS Lambda.
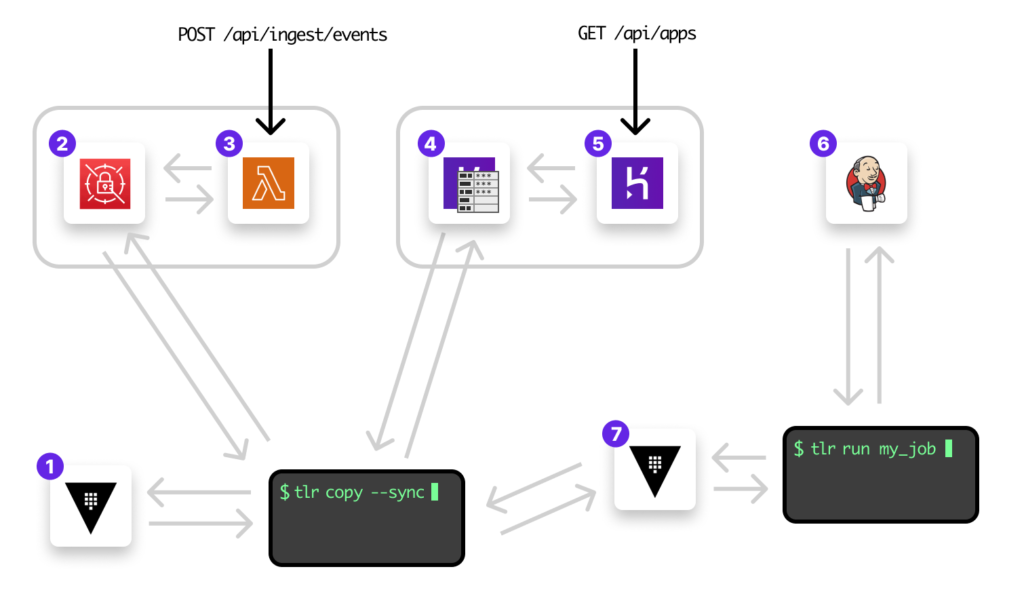
Heroku is the poster child of what we know today as “gitops”. It empowers small teams to be extremely effective and fast. In addition, AWS’ Lambda is arguably the most common and simple way to solve for scale dynamically today by providing teams with a “fire and forget” solution for scale.
These days, the fact that this means running on “multiple clouds” doesn’t even register. You keep the codebase in a monorepo, same language (say, node.js + Typescript), use fantastic tooling like lerna, serverless, and the heroku toolchain, and you don’t feel any friction or overhead.
In terms of how you built this system, more often than not you’ll be gluing lots of APIs. From using AWS itself to services such as Mailgun, Sentry for monitoring, and others. Sooner than later, you’ll have to reason about how to maintain their secrets and access detail.
In the diagram below, let’s look at one example of how to safely and responsibly maintain secrets throughout this architecture.
If we take Heroku as our example of PaaS (platform as a service), a typical app commonly has various environments or stages:
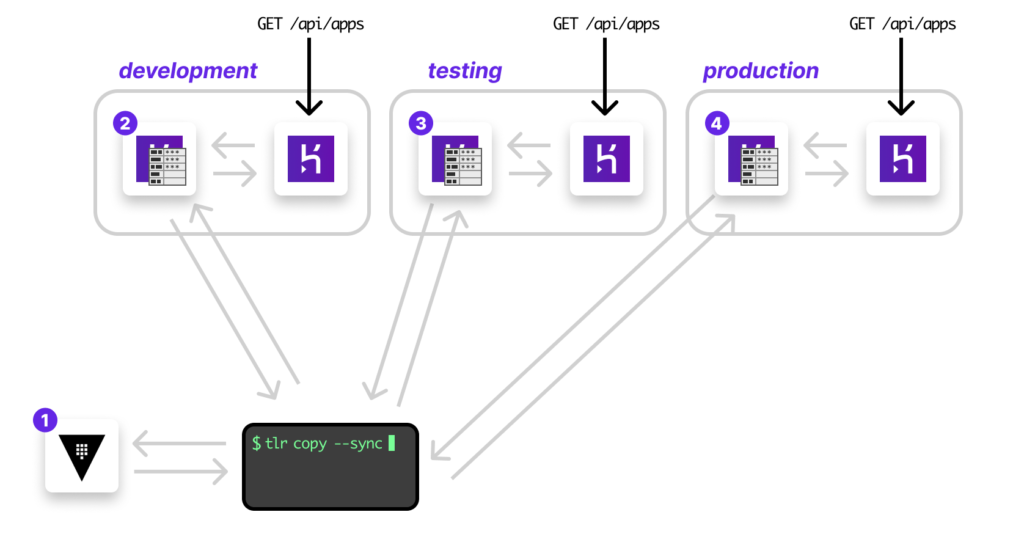
Specifically for this example, it is sometimes necessary to share some settings (not necessarily secret settings, but perhaps private settings). It is also common to confine secrets dedicated for each environment (a production database is very much separated from all other databases, for example).
In all of these scenarios, we use Hashicorp Vault as a source of truth (or system of record) and from there, sync various other services with it:
As a general principle, it makes sense in some cases to mirror the set of secrets and in other cases to pick and choose what you want to copy to keep in sync.
It is worth noting that we could have picked another vault or a different service to be the source of truth. However, as long as we create a reasonable path and flow of data, it becomes a good architectural practice. As opposed to no guideline at all, which encourages chaos in saving, maintaining, and reasoning about data. In this case very sensitive data.
Secret drift is when you have knowledge of the set of secrets that are needed in a specific context. These are true at one point in time. As time transpires this knowledge and reality grow apart.
For example, you might require that production database credentials are available and visible only to production environments. However, one day you realize someone made a manual copy of it to staging so that they could reproduce a production issue.
Another example is when you might require that your Jenkins cluster never see any secrets other than a very specific set of API tokens that you’ve approved. Until one day you realize these tokens are no longer valid, and a rotated set of tokens were not updated to that system.
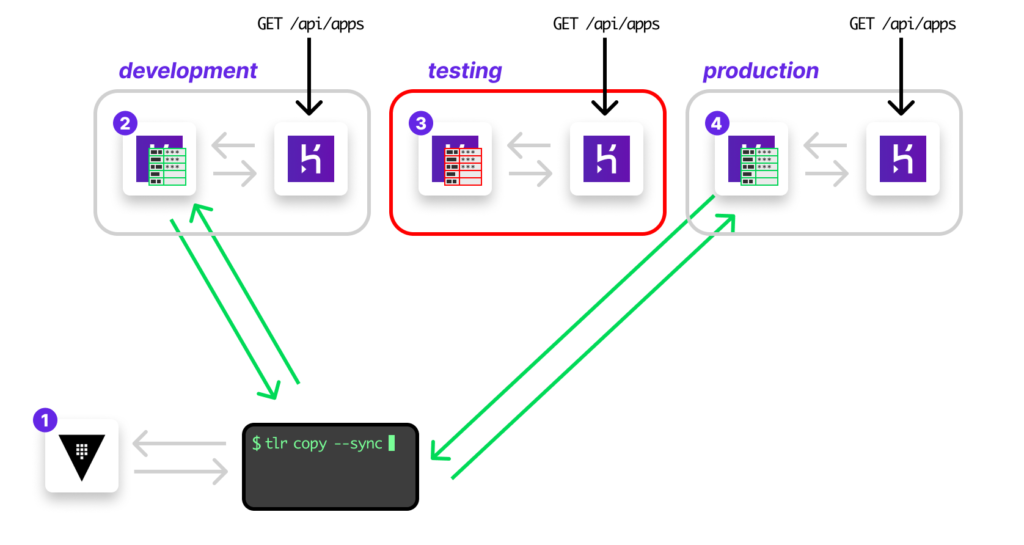
The problem of secret drift or more generally: settings drift can happen due to several reasons:
.nev files, ad-hoc key stores, password apps such as 1password, and others. In this case, drift is a by-nature and by-design; there’s virtually no way to resolve it other than cross your fingers and hope no one makes a mistake.You can grab a release from Github or use Homebrew:
$ brew tap spectralops/tap && brew install teller
Alternatively, if you’re setting up a CI pipeline, you can use Github Actions:
- name: Setup Teller uses: spectralops/setup-teller@v1 - name: Run a Teller task (show, scan, run, etc.) run: teller [task] [args]
You can check your installation by running teller version:
$ teller version Teller 1.3.0 Revision f49ff9dfd0cdc049ec7450b7c31bbf880746d99d, date: 2021-06-08T09:13:27Z
Teller lets you mix multiple different types of secret stores and key-value stores, and have many stores of the same type as well all in the same place.
You start by defining your various providers and creating a mapping that serves as metadata. This metadata is used by Teller as instructions for how to: show, copy, sync, and run process using these secrets or values.
The benefit is that you create one mapping for your architecture, which is risk-free to support modern architectures and best practices. For example, this is safer than .env files which helps you support some good practices such as 12-factor apps but actually contain your secrets verbatim.

After you’ve set up your teller.yml config with the built-in wizard, you would end up with something like this:
project: project_name
opts:
stage: development
# remove if you don't like the prompt
confirm: Are you sure you want to run in {{stage}}?
providers:
# uses environment vars to configure
# https://github.com/hashicorp/vault/blob/api/v1.0.4/api/client.go#L28
hashicorp_vault:
env_sync:
path: secret/data/{{stage}}/services/billing
heroku:
env_sync:
path: billing-{{stage}}
This configuration says that we recognize our Vault and Heroku as two places where secrets appear (or any key-value material for that matter). We’re treating Heroku as a separate deployment per stage, while Vault keeps each environment in a different sub-tree (just by our use of the {{stage}} template variable).
This simple configuration enables us to perform multiple different operations such as:
$ teller show
This command will print out a nice formatted list of keys and values (masking the values)
Here’s a nice exercise you could do by setting up two local .env files that are different, and seeing how the drift analysis works.
To detect mirrored providers (you expect providers to mirror one another):
$ teller mirror-drift --source global-dotenv --target my-dotenv Drifts detected: 2 changed [] global-dotenv FOO_BAR "n***** != my-dotenv FOO_BAR ne***** missing [] global-dotenv FB 3***** ??
Teller also has an ability to link between specific values in different providers, forming a graph of relationship. To detect providers that are expected to mirror through a graph, such as in this configuration:
providers:
dotenv:
env_sync:
path: ~/my-dot-env.env
source: s1
dotenv2:
kind: dotenv
env_sync:
path: ~/other-dot-env.env
sink: s1
Where a source and sync relationship is labeled as s1, we use:
$ teller graph-drift dotenv dotenv2 -c your-config.yml
This accepts any number of providers to participate in the graph building process and then, detection.
In both methods, drift detection will enumerate all of your providers and cross-check one against the other, finally showing you a summary of where you stand.
You can also run drift analysis as a regular part of your CI/CD pipeline, promoting security through the pipeline. It should indicate no drift or drift as the appropriate UNIX exit code and you could break a build using that.
Here’s an example of how to incorporate drift detection as part of your Github CI pipeline using the Teller Github Action:
- name: Setup Teller uses: spectralops/setup-teller@v1 - name: Run a Teller task (show, scan, run, etc.) run: teller mirror-drift --source global-dotenv --target my-dotenv
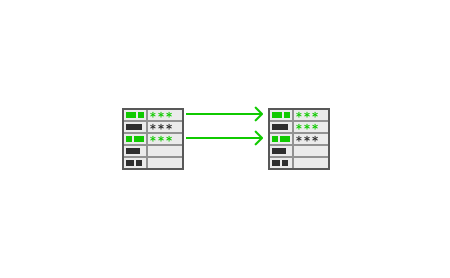
You can copy from one provider to one or more destinations by running:
$ teller copy --from vault --to heroku
This will copy specifically mapped keys in the source provider to specifically mapped ones in the target providers, which is common when you want to only mirror a set of selected keys.
With this technique, you can run a scheduled job that will always maintain parity between providers (because keys are well-known and specific).
You can perform a full sync copy (all keys to all keys) which is common when you want to fully mirror providers with:
$ teller copy --sync --from vault --to heroku
By using Teller, you’re not only acknowledging a more modern approach and best practices to using secrets but putting the right tooling behind it. Teller is open source, and we’re accepting pull-requests for new providers, as well as requests for more workflows.

Did you know that the household data of 123 million Americans were recently stolen from Alteryx’s Amazon cloud servers in a single cyberattack? But the blame

Software developers face a constant barrage of cyber threats that can compromise their applications, data, and the security of their organizations. In 2023, the cyber threat

If you are a developer in the current cybersecurity climate, you already know your application’s security is paramount. But have you considered the risks associated with