
Top 9 Vendor Risk Management Software for Infosec Pros in 2023
No single organization can master all trades, which is why their success hinges heavily on their vendors. And if vendors are crucial for your business operations,
While modern businesses depend on data to stay ahead of the competition, data alone isn’t enough. They also need efficient search engines to quickly index and search through millions of records to make sense of the data. Today we’re looking into SOLR and Elasticsearch, the two heavyweights in this domain, to compare their performance differences and use cases.
Before getting into more detail about which search engine might be right for you, let’s define SOLR and Elasticsearch to get an idea of how they work:
Apache Solr is an open-source licensed search engine built on the Apache Lucene library. It uses HTTP requests to provide all of Apache Lucene’s search engine capabilities, including full-text search, real-time indexing, database integration, hit highlighting, and rich document handling.
Among its key characteristics, the following stand out:
Elasticsearch is an open-source licensed search engine that uses the Apache Lucene library and adds its ability to scale horizontally. It provides indexing and search capabilities using the Apache Lucene library with its extensible array of REST APIs. It bases its representation of documents in JSON format, which has quickly become popular amongst the community.
The following features stand out in terms of what Elasticsearch brings to the table:

SOLR and Elasticsearch come with their own set of advantages and disadvantages. Here are some important criteria you should consider when comparing these solutions:
Even though Solr and Elasticsearch have similarities in terms of the library that powers the tool, native differences set the two solutions apart. Let’s look into some of the common differences you may need to consider before deciding which one is right for you:
SOLR uses XML to return responses via HTTP requests. It gets the job done, but it is quite an outdated way of returning the response. However, with the newer releases of SOLR, JSON is also supported to make for a flexible design.
Elasticsearch supports JSON natively to return responses via its REST APIs. It also supports sending the request via JSON, which increases the customization capability and usability of the solution.

Elasticsearch comes with Zen to provide the native capability to scale horizontally. It makes it much easier to cluster multiple nodes and does not require any manual intervention to rebuild a cluster during a failure or addition of a node. Zen is also responsible for handling complete fault tolerance within the cluster, and Elastic recommends having at least three dedicated master nodes.
On the other hand, Solr does not have built-in capabilities to manage clusters and requires an additional service such as Apache ZooKeeper to handle cluster coordination. Before adding a new node to the SOLR cluster, the existing cluster needs to know what Apache ZooKeeper ensemble to connect to; this requires manual intervention.
Elasticsearch is more dynamic with its shard and indices placement. Additionally, its built-in capabilities allow Elasticsearch to move around shards within the cluster upon a particular trigger. For example, the Elasticsearch cluster will decide to move the shards around the cluster as it detects an introduction of a new node to the cluster or detects the removal of a node from the existing cluster.
However, older versions of SOLR do not take any dynamic actions when they detect an addition or remove a node from an existing cluster. SOLR version 7 and later introduces AutoScaling API, where we can define cluster-wide rules to control shard placement. However, without these rules, SOLR does not automatically perform any shard reorganizations.
Searching is inherently available within both solutions since they leverage the same Lucene library. However, both solutions have different approaches to providing search functionality.
SOLR focuses on text-oriented searches using highly configurable parsers. In contrast, Elasticsearch allows you to implement queries for searches easier by hiding the implementation complexity, but this approach compromises the flexibility of the actual query. Elasticsearch also allows more than text-oriented searches by providing advanced features such as filtering and grouping.
Since both tools use the same underlying library, they share the same concept of segments. Segments are pieces of the Lucene index that is composed of various files. Segments also consist of data and are mostly immutable.
SOLR maintains global caches – a single cache instance of a specific type of a shard for all its segments. If a single segment changes, SOLR requires the entire cache to be invalidated and refreshed. This process takes up hardware resources and time.
Elasticsearch maintains individual caches per segment, making the cache update process less resource-intensive once a segment changes. Elasticsearch only requires invalidating caches and refreshing a single cache portion rather than the entire cache.
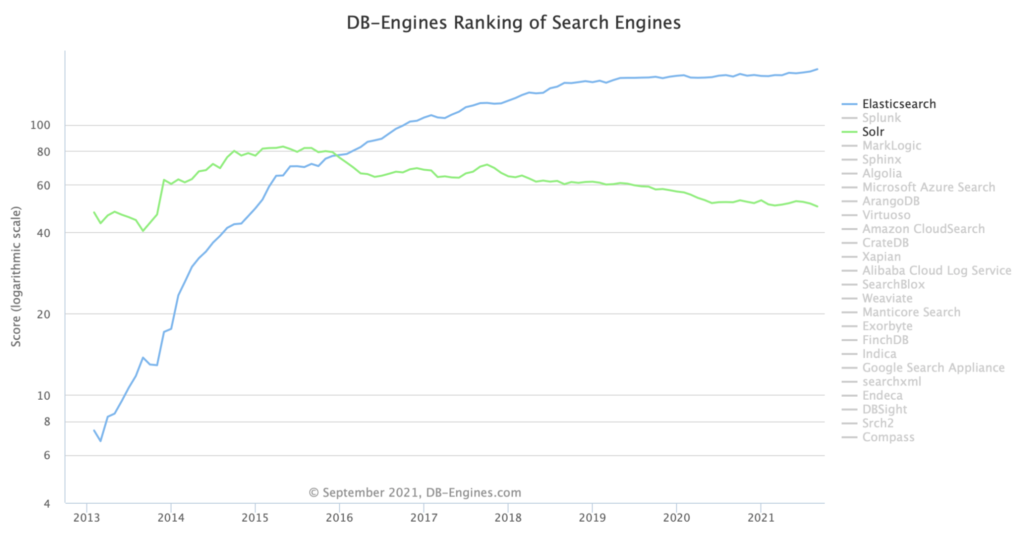
At first, when comparing SOLR and Elasticsearch, there seems to be a clear winner for modern applications and use cases: Elasticsearch comes out on top due to its flexibility, ease of use, scalability, and essential enterprise environment requirements.
Perhaps its popularity is also due to the fact that Elasticsearch is more approachable for new users, easier to scale, and has better querying and analytics capabilities than SOLR. However, these databases can search full-text and reach rich documents using the Apache Tika library. Besides, you are best positioned to understand your team’s priorities and unique needs. So we hope you’ve found this breakdown useful in assessing how to select a tool that can help your business make the most of your data.
Looking for more tips on how to serve the data needs of your organization? Then we invite you to learn why Big Data security starts at the code level, and stay tuned for more tips and tricks for software developers and security professionals on our blog.

No single organization can master all trades, which is why their success hinges heavily on their vendors. And if vendors are crucial for your business operations,

Integration is an indispensable aspect of modern software development. As software applications become more complex and interconnected, every component must work seamlessly together like a game

Modern companies are rapidly adopting cloud applications and services due to scalability, cost savings, and faster time to market. DevOps teams and developers must deliver fast,