
10 Types of Vendor Related Risk Cloud Native Organizations Need to Manage
If you are a developer in the current cybersecurity climate, you already know your application’s security is paramount. But have you considered the risks associated with
Dealing with data leaks after they happen can be a pain. Not only are you tasked with trying to figure out where things went wrong, but you’re also dealing with the financially damaging effects of data and information potentially being used in malicious ways. And that’s just the tip of the iceberg.
No one likes to deal with the after-effects of a data leak, even if they have a proper data breach response plan prepared. Results of a data leak can include financial losses, reduced trust on behalf of your users, diminished reputation, and costs that come with trying to figure out what happened and why it happened.

When it comes to dealing with data leaks, prevention is always the best strategy. But how do you protect your software, applications, and business from data leaks? What can you do as part of your due diligence to mitigate a potential disaster from occurring?
Here are 8 proven strategies that you can use to help prevent data leaks from happening through your code, software, and infrastructure setups.
If sensitive data falls into the wrong hands encryption becomes the final line of defense against malicious users. The purpose of data encryption is to protect data confidentiality. This means that only authorized users with the right keys can access the decrypted data.

It sounds obvious but some applications still don’t employ enough encryption on data, if there is any at all. There are the usual data points that we should encrypt like passwords and credit card details, but it doesn’t need to end there. Encryption can and should also be placed on roles and user-based data to protect against unauthorized access or hijacking.
Your technology stack is accessed not only by human users but also programmatically by other software. This can be done in three ways.
First, by mindfully connecting to other software (through APIs, SDKs, etc.) and granting access through a specific key, which is like a programmatic username and password.
Second, by mistake. Providing misconfigured access to a software where you did not meant to provide it at all or meant to provide a different level of access.
Third, by cyber attackers who do not and should not have any access. Attackers will usually look for entry ways into your software stack by finding its weakest link. Often, this is accomplished by finding those mistakes we made in #2.
Protecting your secrets from cyber attackers looking to turn them into exploits will only get you so far. Misconfigured code can still leave you open for attack. A comprehensive secret protection strategy should not only protect and manage your secrets but also monitor your code for places where those secrets are not used correctly and provide misconfigured access.
Our software and applications are all connected over a network. While we often worry about the data during transit, security vulnerabilities can also occur at the endpoints where data is sent and received.
The devices at the endpoints themselves can also be the weak links that facilitate data leaks. This means your users’ laptops, tablets, mobile phones, and network-enabled devices can become beacons for leaks to occur. This can be done through malware programs on the devices that they may not be aware of, or accidental sharing of confidential data.
While a users’ device can feel like it’s out of scope and not within your control, there are certain things you can do to secure your endpoints. One way is to implement a client and server model where the user only has access to the data via authorized applications only.
These authorized applications may come in the form of locally installed software. If access is through a common application like a web browser, whitelisting devices that are allowed access can also mitigate potential data leaks. This means that if an unauthorized device gains access, the user is alerted to this and can proceed to block access if the new source is foreign.
The usual way to secure access to data is via a username and password. But that’s accessibility control at its most basic. Not only that; some users have their username and passwords saved on their devices, which is a walking vulnerability in itself.

So how do you increase the security on application accessibility? A proven way is to implement multi-factor authentication. This means that in addition to the usual username and password combination, the user is required to provide a single-use authentication code that can be sent via text message to an authorized number or through an authorized device with a dedicated MFA app.
While these extra steps may appear cumbersome at first, it is becoming commonplace in spaces like network access, banking, and private messaging applications.
Sharing information within the organization is often encouraged for communication purposes. However, good internal content control can prevent sensitive data from unintentionally slipping out.
You may trust your employees but not all of them may be versed in matters of security, or realize the importance of the information sent to someone who shouldn’t have access. One way to prevent mishaps from occurring is to place blocks, filters, and alerts against common communication tools like email and chat applications.
For application and software-based data, pipelines and process flows can be set up to ensure that sensitive information like encryption and access keys remain private and accessible only to those who are authorized to it. This is because it’s easy to publicly publish keys to public repositories if important file exclusions are not put in place.
To prevent data loss, you need to know what data you have and what data you need to protect. Sometimes, this data is collected in a way that is not clearly defined and can exist in a contiguous state. This can leave your data out in the open and in vulnerable spaces.
Data leaks can happen if you don’t have a system that can assess and prioritize data and its potential risks. Data discovery engines can be used to shift through the content, classify and define their purpose for existing. When you do this, it means that you can proceed to secure it at the right access levels.

Digital fingerprinting is a growing initiative in data security that allows your organization and your users to ensure that the person accessing the data doesn’t remain truly anonymous.
What this means is that both parties are always aware who is accessing the data and at what capacity. A digital fingerprint is a data-driven identifier that has tracking abilities and can detect access anomalies. Not having the right digital fingerprint can help trigger system alerts and notify the owner of the data.
The major benefit of digital fingerprints is that it is persistently accurate and can exist across multiple browsers and applications. This means that the implications of techniques that try and cloak a user’s real identity such as IP address masking, VPN, and cookie manipulation, are less effective.
Manual work is the death of productive work. When developers, engineers, and employees are stuck doing repetitive tasks it can lead to complacency and errors.
Automating your procedures and pipelining your processes reduces the ability to deviate. When an issue arises, the process and procedures can be modified and improved. It creates a digitized checklist that is machine-driven and if an anomaly or error arises, alerts can be configured to notify the right people.
Systems without automation and anomaly detection are prone to unmonitored failures, which can lead to ongoing data leaks and compromise your data security.

Automation can be as simple as implementing CHRON jobs on the server to check network connection integrity, or as complex as running cloud-driven pipelines that monitor how data transitions between the different layers.
Data leaks are costly when it happens. When you implement preventative measures on your systems, software, and applications, it is an investment against potential future failures.
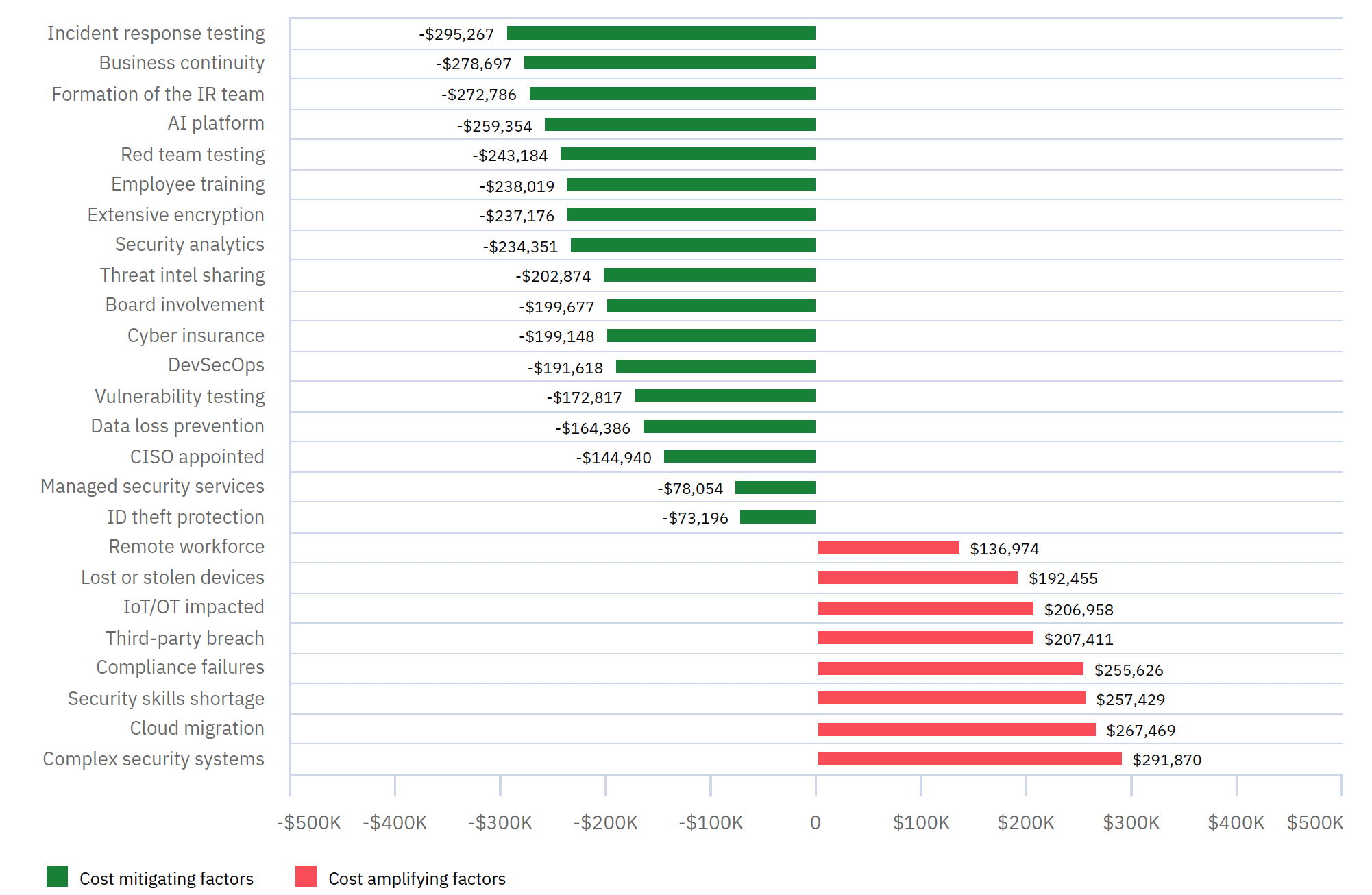
When sensitive data becomes public or is accessible by unauthorized sources, it is hard to retract it. So if you want to keep something out of reach from potentially malicious users, consider at least one or all of the above listed strategies today.

If you are a developer in the current cybersecurity climate, you already know your application’s security is paramount. But have you considered the risks associated with

The trouble with allowing developers to deploy code directly to production is that security threats are often overlooked in the process. These vulnerabilities only show up

Rapid digitalization and increasing remote business operations place a significant burden on developers, who are continuously pressured to push out software faster. As a result, CI/CD