
Top 12 Open Source Code Security Tools
Open source software is everywhere. From your server to your fitness band. And it’s only becoming more common as over 90% of developers acknowledge using open
Artificial intelligence has long been heralded as the solution to all our problems: “Don’t worry about it – let the computers do the worrying for you”. But is it, really? The short history of AI is littered with virtual corpses and epic fails.
There is one software company that has been relentlessly trying to use AI/ML technologies to solve more and more problems, in general, and for developers in particular. That company is Microsoft. Most recently, Microsoft, in partnership with OpenAI, created CoPilot.
CoPilot looks and feels like Microsoft’s all-time effort to improve Intellisense, its code-completion IDE plugin. However, this time the completion is actually writing complete code bodies instead of completing keywords. Apparently, this effort was made possible by applying modern ML models, provided by OpenAI’s GPT-3 models, on GitHub public data, at a massive scale.
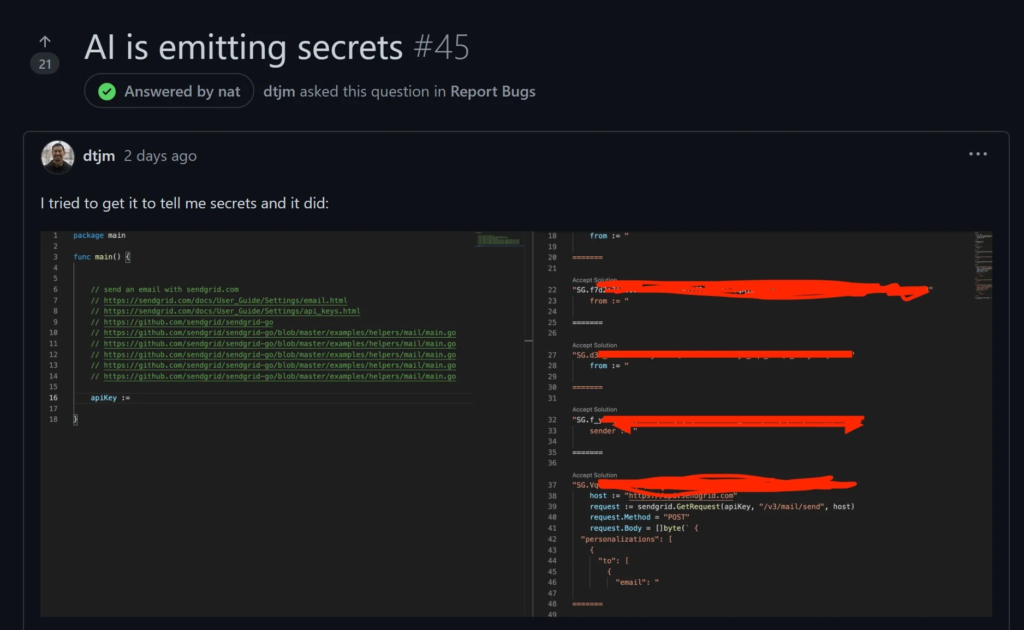
According to the chatter on Reddit and Twitter, it seems that this data had not been triaged first. This means that artifacts like secrets and copyrighted code are being suggested as completion options. Which is very, very bad. We can see this happening right now. It was first reported by Sam Nguyen, a SendGrid engineer (djtm on GitHub):
We can also reproduce copyrighted code as Armin Ronacher, creator of Flask, reports here:
I don’t want to say anything but that’s not the right license Mr Copilot. pic.twitter.com/hs8JRVQ7xJ
— Armin Ronacher (@mitsuhiko) July 2, 2021
Microsoft is familiar with the domain subject, with CodeBERT being a serious entry into the CodeSearchNet effort. However, Microsoft did take down an AI project in the past. It was in a case involving a chatbot that turned out to be “evil”. It exhibited machine learning of both the positive and negative aspects of human behavior.
The field of “Big Code” or ml4code is on the rise in recent years. In the past year alone, we’ve seen very advanced research being published that represents a gigantic leap in how we understand code, due to advancements in deep learning. Studies such as the recent CoTexT (2021) that deals with tasks like code generation, classification, and defect detection, as well as more language-specific papers like DeepDebug (2021) that deals with taking advantage of specific Python stack traces and other Python data to debug programs.
All code secrets are important. Including the ones that don’t seem like it at first. One set of credentials or an API secret in a public repository can quickly snowball into a costly data leak. And there’s no shortage of examples.
In 2021 an ethical team of hackers researched the security of the Indian government. When they found a .env file in their git repository. Then, they escalated their access using commonly found tools, until they had full access.

Though it’s very hard to predict where exactly code secrets may hide, there are certain file types that are prone to such issues.
Contrary to humans, AI/ML does excel in secret scanning. Moreover, unlike entropy checks and regular expressions, which are essentially educated guesses, machine learning works by training an algorithm on a large, curated data set of previously discovered secret leaks.
A machine learning algorithm evolves through additional data sets and user-generated feedback. As the algorithm is trained, false-positive reports are reduced, and previously hidden secrets may be revealed.
At Spectral, we employ machine learning to enable our users to better detect secrets in their codebase. Since this is not our first rodeo building AI-assisted technology we foresaw the issues of learning from sensitive code and copyrighted data, as well as other common new-generation issues with deep learning and ethics.
Being that we’re a security-first company and that we never get permissions to your private codebase we don’t copy, store, or process it outside of your servers, ever. That presents a monumental challenge: where to get the data to learn from?
We invested over a year in answering this question. We built CodeSynth — a proprietary platform that is tasked with the sole purpose of generating code, configuration, and developer-related data that we can learn from. We used public code and datasets with the correct, triaged license to build hand-tagged blueprints for CodeSynth, for over 6 months (and still going).
Finally, we make sure that our models don’t train on full-bodies of text, and don’t try to classify full bodies of text. Instead, they work as an ensemble of purpose-built, highly specialized models that “vote” for a decision on a given snippet of text. In this way, we side-step completely the challenges that we mentioned that relate to learning from Big Code.
While the final note of AI as a writing-code machine (to replace us all!) has yet to be played, we as an industry are just getting started. And it’s obvious.
If we consider the subject from a risk-based perspective, we realize that whatever technology out there that learns from our code right now, and in the future, it will also learn from our mistakes, and reproduce those faithfully.
It’s a new motivation and a valid driver to think about mistakes in code being exposed implicitly by these very new-generation solutions. Solutions like Spectral can help you locate and mitigate mistakes and code risk, as well as block potential data breaches. After all, AI may not be the solution to all our problems, but it can be leveraged to help us remediate at least some — like code secret leaks.

Open source software is everywhere. From your server to your fitness band. And it’s only becoming more common as over 90% of developers acknowledge using open

It’s easy to think that our code is secure. Vulnerabilities or potential exploits are often the things we think about last. Most of the time, our

Continuous integration and delivery are necessary in any production level software development process. CI/CD are more than just buzzwords. Rather, it is a fully-fledged methodology of